Dirty Pixels
Грязные пикселы
James F. Blinn
IEEE Computer Graphics & Applications, July 1989, pp.100-105
Однажды я увидел изречение, которое висело на какой-то стене и гласило что-то вроде …
Выполнение операций с плавающей точкой напоминает перемещение кучи песка. Всякий раз, когда вы делаете это, вы теряете немного песка и подхватываете немного грязи.
Если это верно для плавающей точки, то в еще большей степени верно для масштабируемых целых чисел. Поскольку пикселы приходится передавать в аппаратуру дисплея, существует несколько способов их "испачкать". На этот раз поговорим о двух из них.
Целочисленные пикселы (Integer pixels)
Давайте начнем с чего-нибудь простого. Нам бы хотелось производить все вычисления с пикселом с плавающей точкой, получая число между 0.0 и 1.0 как желаемую интенсивность пиксела на дисплее. Типичные сегодня дисплеи помнят пиксел как 8-разрядную величину со значением от 0 до 255. Как нам закодировать желаемую интенсивность, которую мы будем обозначать как D, в целочисленное значение пиксела, которое мы будем обозначать как I?. Самое простое - это сопоставить диапазон (0.0 - 1.0) с диапазоном (0 - 255) и выбрать ближайшее целое число. Вот по такой формуле:
I = int(D * 255. + .5)
Функция int берет целую часть от числа с плавающей точкой. Нужно прибавить 0.5, чтобы округлить ее до ближайшего целого.
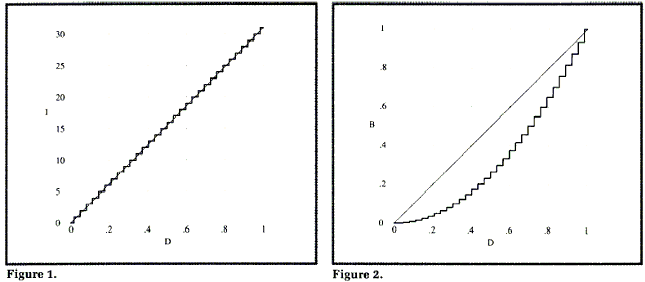
Чтобы показать, как могут вкрадываться ошибки, я представлю несколько графиков на рис. 1 - 4. Но сделаю я их попроще специально для визуализации (о, боже, как я люблю это слово); хотя я и выписал все формулы с числом 255, рисунки будут построены с максимальным значением пиксела 31 (5 бит), чтобы эффекты проступали более явно.
В любом случае, процесс перевода в целые числа порождает то, что называют ошибкой округления. Чтобы показать, как все это выглядит, я изобразил D в зависимости от I на рис. 1. В идеале мы хотели бы иметь прямую линию; получили же мы ступеньки лестницы.
Гамма (Gamma)
Аппаратура дисплея принимает 8-битное значение, преобразует его пропорционально в напряжение и передает на монитор. Преобразование происходит в соответствии со следующей формулой:
V = I / 255.
Жизнь существенно усложняется, когда это напряжение используется для управления монитором. Проблема в том, что интенсивность или яркость отображения на монитор не пропорциональна напряжению, которое на него подается. На самом деле результат будет примерно таким
B = αVγ
Ручки яркости и конраста действительно управляют величинами α и γ, но не так как вы возможно предполагаете. Ручка яркости воздействует на γ, а ручка контраста - на α. Хоть и странно, но именно так. Следовательно, значение γ меняется, но в мониторах, с которыми мне доводилось иметь дело, изменяется оно в диапазоне между 1 и 3, причем 2 - вполне приемлемое среднее значение. (В литературе упоминаются некие стандартные значения, напр., 2.4 или 2.7, но существа дела это не меняет - это отнюдь не 1. В дальнейшем я буду использовать &gamma = 2.)
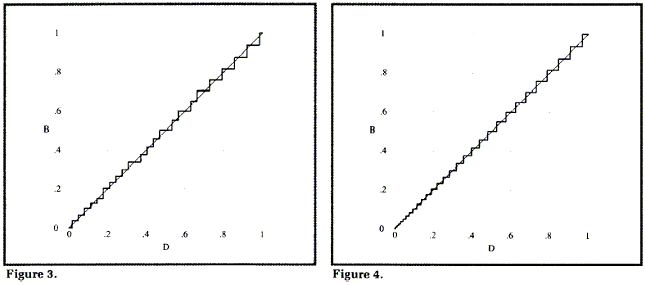
На экране дисплея отображается интенсивность (нормированная к максимальному значению 1.0), т.е.
B = (I / 255.)γ
Простая передача пикселов на дисплей приводит к крайне нежелательному отклику по интенсивности, что и показано на рис. 2. Нужно отдать дань человеческой системе восприятия, которая картинку, отображенную таким образом, узнает, хотя бы по яркости и контрастности.
Гамма-коррекция (Gamma Correction)
Чтобы решить эту проблему, нам необходимо заранее скорректировать те искажения, которые вносит монитор. Проще всего использовать аппаратное средство: цветовую карту или цветовую таблицу-палитру. Это еще 256 слов памяти, вложенные в дисплей. Каждое значение пиксела используется как адрес в этой памяти, а содержимое памяти как раз то, что посылается в Ц/А преобразователь. Чтобы скорректировать гамма-дисторсию, мы просто заносим в таблицу обратную гамма-функцию. Напр., если слово в цветовой таблице состоит из 8 бит, то туда заносится величина
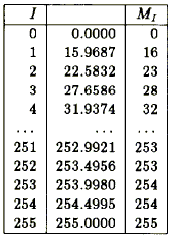
MI = int((I/255.)1/γ * 255. + .5)
При таком переходе к целым числам ошибка округления станет еще больше. Мы начали с желаемой интенсивности D, закодировали ее 8-разрядным числом, пропустили его через цветовую таблицу, подали напряжение на монитор и, в итоге, получили фактическую интенсивность B, которая изображена на рис. 3. В некотором роде мы добились линейности, но при ближайшем рассмотрении результат выглядит довольно безобразно. Почему?
Почему мне это не нравится
Нужно немного разобраться с цветовой таблицей. Обычно пиксел кодируется 8-ю битами, и на выходе цветовой таблицы только 8 бит. Следовательно, если с помощью цветовой таблицы производится не тождественное, а какое-то другое пребразование, происходит потеря информации.
Например, глянем на несколько первых и последних строк в цветовой таблице для γ = 2. Средний столбец в следующей таблице показывает значение (I/255.)1/γ * 255. перед округлением до целого значения MI .
Заметим, что в начале таблицы, при малых значениях, доступные аппаратные уровни интенсивности с 1 по 15 вообще нельзя сгенерировать. А при высоких значениях каждая пара значений в буфере кадра отображается в одну и ту же аппаратную интенсивность.Фактически эта таблица позволяет использовать только 194 из 256 допустимых аппаратных уровней интенсивности. Таковы потери.
Согласованность
Можно сделать лучше. У нас есть метод. Просто нужна согласованность с аппаратурой.
Прежде всего, занесем тождественное преобразование в цветовую таблицу. Затем закодируем D непосредственно в значение пиксела так, чтобы генерировалась ближайшая доступная аппаратная интенсивность. Один (правда, медленный) способ осуществить это намерение приводит к формуле
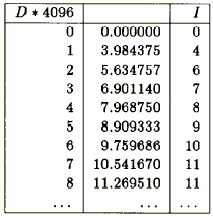
I = int(D1/γ * 255. + .5)
В результате такого нелинейного кодирования получается функция, показанная на рис. 4; значительно менее судорожная.
Сам факт, что точки разрыва между целочисленными значениями пиксела распределены неравномерно - это другой впечатляющий эффект. Ступеньки становятся все меньше и меньше по мере того как значение D становится ближе к нулю. И это хорошо, поскольку именно в этой зоне большее разрешение в интенсивности. Получается что-то вроде логарифмического квантования (которое многие рекомендуют, но я пока не нашел никого, кто бы это реализовал).
Я же сделал это для фильмов о космических полетах, поскольку в моем дисплее было только 32 уровня интенсивности, и ничего более совешенного в данный момент я не знаю.
Конечно, вычисления по этой формуле покажутся медленными. Поэтому в какой-то момент, я реализовал эту формулу для большой просмотровой таблицы (lookup table). Я промасштабировал D по длине таблицы и использовал целую часть как индекс таблицы. Каждая строка таблицы всего один байт, и я позволил себе иметь таблицу, в которой 4096 строк. Но даже этого недостаточно; даже при такой таблице теряется разрешение в верхней части (при малых значениях). Пикселы со значениями 1, 2, 3 и 5 никак нельзя воспроизвести. Ниже пример такой таблицы. Как и прежде в среднем столбце значения с плавающей точкой до того, как они будут округлены до целочисленного байта I.
Есть более хороший, но окольный путь. Чтобы выйти на него, давайте прежде решим обратную задачу.
Как вернуть пикселы
Предположим, что нам нужна комбинация вычисленного изображения с тем, которое уже находится в буфере кадра. Перевод значения пиксела в соответствующую эффективную интенсивность лучше всего делать с помощью просмотровой таблицы. Поскольку имеется всего-то 256 возможных значений пиксела, таблица не будет слишком большой. Таблица содержит функцию
TI = (I / 255.)γ
Первые и последние строки в этой таблице будут такими:

Кодирование пикселов
Теперь мы можем еще раз рассмотреть процесс кодирования пиксела, как обратную просмотровую таблицу. Если известно желаемое значение интенсивности, мы просто находим ближайший к нему элемент в таблице и используем номер этой строки как значение пиксела.
Значение где-то посредине между TI-1 и TI - это точка перехода, где заданное значение пиксела более близкое к I-1 меняется на значение пиксела более близкое к I. Поэтому, прежде всего сделаем таблицу, в строках которой
AI = (TI - 1 + TI) / 2
и воспользуемся совсем простым методом двоичного поиска, заимствованным из книги Jon Bentley "Programming Pearls" (Addison-Wesley, Reading, Mass., 1986, p. 87 - книжка действительно хорошая). Мы начнем со значения D с плавающей точкой и закончим значением пиксела I.

Обратите внимание на тривиальный результат алгоритма: значение пиксела втиснуто в диапазон от 0 до 255 (т.е. всякие переполнения автоматически обрабатываются). Если вы захотите, то вы сможете, используя этот метод, провести и логарифмическое квантование, просто заменив значения в этой таблице.
Конечно, этот метод несколько медленнее просмотровой таблицы, но он существенно аккуратнее. Я обнаружил, что время выполнения убивается, в основном, в обычно нетривиальной программе синтеза изображения на вычисление значения D для данного пиксела. И все-таки, восемь сравнений с плавающей точкой на один кодируемый пиксел чуточку многовато, что приводит нас ко второй фазе рассуждений.
Масштабированные целые числа
А теперь кое-что (казалось бы) совсем другое. До сих пор я говорил о желательной интенсивности пиксела D, как о числе с плавающей точкой. Так я и думал до недавних пор. Когда я заканчивал университет (в эпоху от PDP-9 до PDP-11, с плавющей точкой), мне никогда не приходилось прибегать к арифметике масштабированных целых чисел. Но теперь, когда я работаю на клонах РС, я вынужден вернуться к этой арифметике. И теперь, когда я думаю об этом, плавающая точка представляется мне, в некотором роде, самоубийственной. Имеется в виду только то, насколько аккуратно вы собираетесь упаковать некую величину в восемь бит?
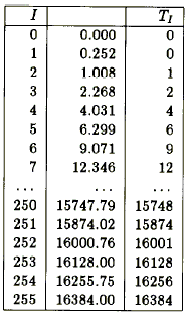
Итак, предположим, что мы хотим представить нашу интенсивность как 16-битовое целое масштабированное число. Каким должен быть масштабный коэффициент? Целесообразно выбрать такое представление, при котором 1.0 будет в точности степенью 2. Разумно также укладываться в относительно небольшой диапазон целых чисел, чтобы не приходиось беспокоиться о переполнении в знаковом разряде. Все эти соображения подсказывают коэффициент масштабирования равный 16384. Для перевода значения D с плавающей точкой в масштабированное целое число J используется формула
J = int (D * 16384. + .5)
Значение 1.0 представляется шестнадцтеричным значением 4000; двоичная точка сдвинута внутрь от правого конца слова. Большая часть дробных чисел компактно укладывается в 14 младших бит. Похоже, что мы, как бы лишились двух возможных бит точности. Насколько это плохо? Разобраться в ситуации можно, посмотрев, хотя бы, на масштабированные целочисленные представления имеющихся аппаратных интенсивностей. И еще, в среднем столбце указана масштабированная интенсивнось перед округлением до целого значения TI .
Потерялось и не используется значение пиксела I = 0, посольку его интенсивность отображается в значение J равное 0. Но нам и не нужны еще два бита, чтобы получить разрешение, позволяющее различать эти две нижние интенсивности. Иначе нам пришлось бы перейти на 17 бит (чтобы представить 1.0 шестнадцатеричным числом 10000). Поэтому следующая таблица - лучший вариант, которого мы могли добиться при 16 битах.
Итак, теперь операция кодирования обходится в восемь целочисленных сравнений, вполне разумная цена.
Как же теперь, в этой новой обстановке, выполнять привычные операции?
Сложение
Просто суммировать:
Jnew = J1 + J2
Умножение
При умножении двух масштабированных целых чисел нужно помнить, что каждый сомножитель несет в себе неявный коэффициент 16384. Поэтому после умножения нужно выполнить деление, чтобы полученный результат был масштабирован только однократно. Поскольку после деления получается еще и дробная часть, необходимо прибавить половинку для округления, что соответствует прибавлению 8192 перед делением. Получается такая формула:
Jnew = (J1 J2 + 8192) / 16384
Теперь-то понятно, почему коэффициент 16384 такой удобный; деление можно выполнить простым арифметическим сдвигом:
Jnew = AShiftRight(J1 J2 + 8192, 14)
Лерполяция
Среди тех, кто многие годы профессионально занимается машинной графикой, самой общеупотребительной оперцией над пикселами считается линейная интерполяция по двум значениям; на профессиональном жаргоне эту операцию назазывают не иначе как "лерп". Она используется при мягком размывнии краев, при показе прозрачности, да и во многих других делах. В контексте чисел с плавающей точкой формула будет такой:
Dnew = αD2 + (1 - α)D1
Чтобы обойтись без умножения, применяют другую, лучшую, реализацию
Dnew = D1 + α( D2 - D1)
Если же мы закодируем все эти величин (включая α), как 16-разрядные целые числа, то просто перейдем к нашей формуле умножения
Jnew = J1 + AShiftRight(Jα (J2 - J1) + 8192, 14)
Но при этом возникает маленькая тонкость. В этом случае обязателно нужно использовать операцию сдвига вместо деления. Причина в том, что разность J2 - J1 может быть отрицательной, и целочисленное деление даст не тот результат, который мы хотим прлучить при отрицательных числах (т.е., -10000 / 16384 = 0, в то время как ASR(-10000, 14) = -1), и как раз -1 нам нужно получить в качестве правильного ответа.
Ошибка в масштабированных целых числах
Какие же другие виды ошибок могут вкрасться в эти операции? Чтобы понять, что же происходит, давайте упростим ситуацию и будем использовать масштабный коэффициент 4 вместо 16384. Другой подход к осмыслению работы с масштабированными целыми числами состоит в том, что пять возможных целых чисел рассматриваются как значки для диапазонов чисел с плавающей точкой, которые заданы в следующей таблице:
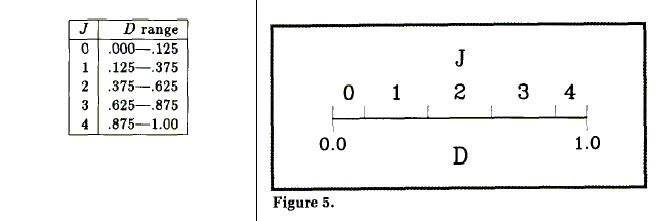
(Обратите также внимание числовую ось на рис. 5.) Отметим один приятный момент в использовании значков: обычная арифметика над значками дает правильный значок для ответа с плавающей точкой. В некотором роде.
Чтобы показать какие ошибки при этом могут возникать, я построил диаграммы для каждой операции на рис. 6 -- 8. Каждый рисунок состоит из трех частей. Часть (a) показывает, что происходит, когда операция выполняется с бесконечной точностью, а затем результат преобразуется в целое число. Часть (b) показывает, что происходит, когда аргументы переводятся в целые числа, и операции выполняются в целочисленной арифметике. В каждом из этих случаев используются бинарные операции, поэтому все возможные аргументы укладываются в квадрат со сторонами от 0.0 до1.0 (промасштабировнные значками от 0 до 4). На картинках квадрат делится на области, в которых ответ представляется целочисленными значками. Проблемные места обнаруживаются при совмещении двух графиков, что и сделано в части (с) каждого рисунка.
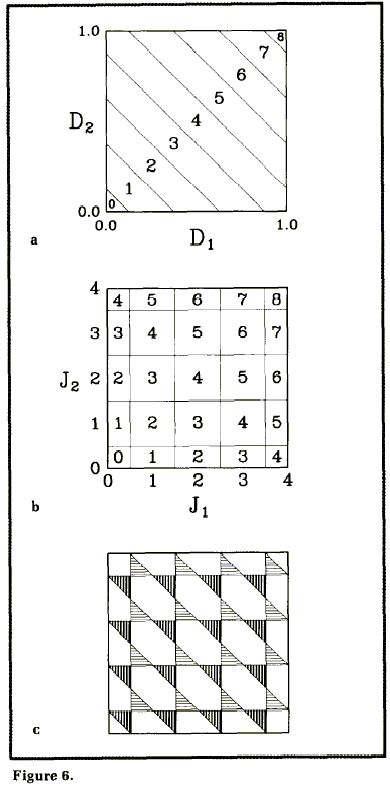
Сложение
На рис. 6 желаемые ответы лежат в диагональных полосах. Для целочисленной версии характерен узор шахматной доски, просто таблица сложения. Наложение обоих графиков дает три типа областей: там, где получился правильный ответ; там, где ответ завышен на единицу (темные области с вертикальной штриховкой); и там, где ответ занижен на единицу (более светлые области с горизонтальной штриховкой). В 75% случаев получен правильный ответ, в 12.5% случев он слишком завышен, и в 12.5% случаев слишком занижен. В целом, по статистике, мы подхватили некоторую грязь, но, по крайней мере, она несмещенная, т.е., когда ее слишком много с одной стороны или с другой.
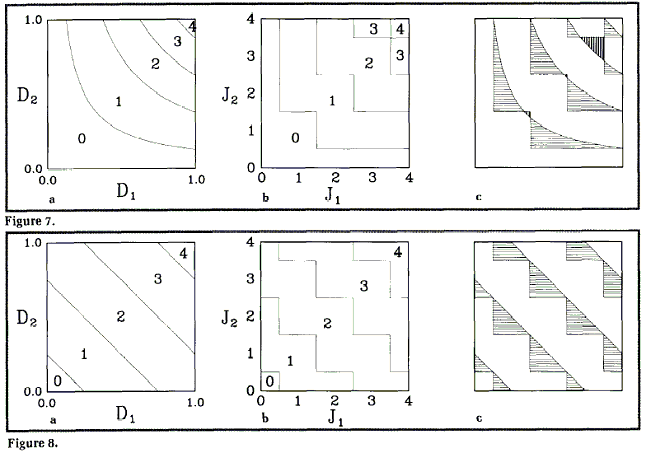
Умножение
Теперь посмотрим на рис. 7. Здесь правильные ответы получаются в 80.7% случаев, в 17.8% случаев ответ излишне завышен, и только в 1.5% случаев излишне занижен. И на первый взгляд -- это не есть хорошо. Кажется, что есть смещение в сторону завышения. Но, на самом деле, все не так уж плохо, поскольку, когда количество бит возрастает, оказывается, что области с завышением и области с занижением все более и более выравниваются. Затруднительно провести точные вычисление, моделирование методом Монте Карло показывает, что при масштабном коэффициенте 16384 проценты будут примерно такими: 80, 10 и10.
Лерполяция
Взгляните на рис. 8, где показана лерполяция с α = 0.5. Вот здесь-то действительно проблема. Правильный ответ получается в 75% случаев, в 25% случаев есть излишнее завышение, а занижения не бывет никогда; другими словами, налицо смещение. И лучше не становится от одного только увеличения количества бит. Пропорции остаются в точности такими же.
Я не знаю как вас, но меня этот факт смущает. Это означает, что лерп-операция, в основе своей, нестабильна. И что же с этим делать? А, в сущносим, ничего. Я думаю так, если я такой хороший парень и так правильно кодирую интенсивности пикселов - I, то могу допустить немного шума при вычислении J. И по большому счету это, дейтвительно, верно. Пока вы не производите угрожающе большого накопления интенсивности в 8-разрядном буфере кадра, от небольшого шума в 16-разрядной версии, скорее всего, ничто не пострадает.
Но есть и возможное решение - последующее псевдотонирование. Всякий раз, когда производится лерп, прибавляется смещение 8191, а не 8192. Это ведет к сещению результата в другую сторону. Было 0% завышений и 25% занижений. Может быть они статистически скомпенсируются. Хорошо ли это работает? Я не знаю. Как это надо сделать? Я не знаю. Может быть кто-то мне подскажет.
Перевод Ю.М.Баяковского
10декабря 2003
| 